How I teach the meaning of (statistical) p-values (without PowerPoint)
- Christian Moore Anderson

- Jan 23, 2024
- 1 min read
Updated: Feb 28
To understand p-values, you must discern a critical aspect: how confident you can interpret data. You must see how the relationship between the means and their data spread can vary, and how this affects your confidence in interpretation. This post is about getting students to distinguish the meaning of p-values.
I begin by drawing a representation of sampling. This is a key concept, but students are often familiar with it due to the exams they sit.
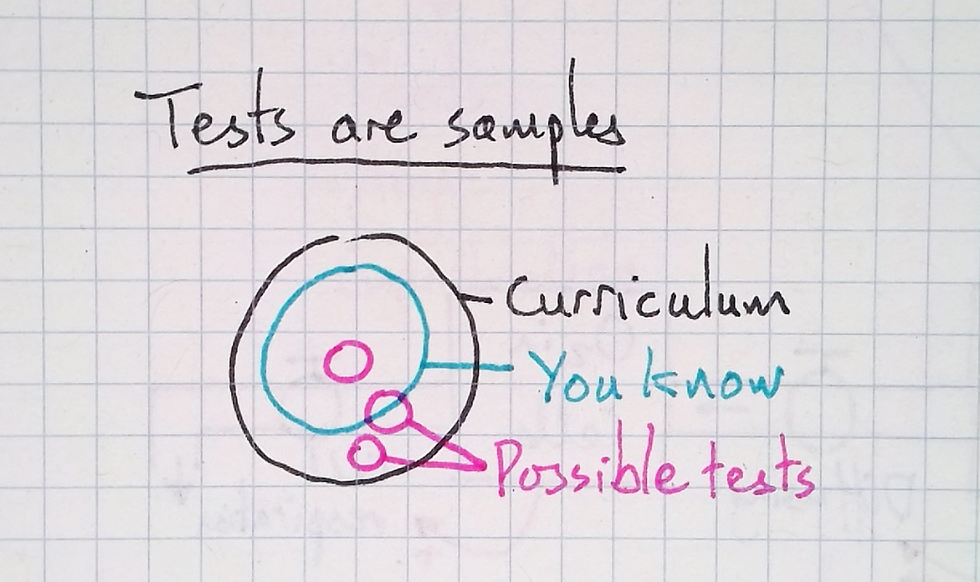
🚨 Update: I've moved to a new home! You can read the newest, updated version of this article on my new website here: https://christianmooreanderson.com/how-i-teach-the-meaning-of-statistical-p-values/


